https://school.programmers.co.kr/learn/courses/30/lessons/86491
프로그래머스
코드 중심의 개발자 채용. 스택 기반의 포지션 매칭. 프로그래머스의 개발자 맞춤형 프로필을 등록하고, 나와 기술 궁합이 잘 맞는 기업들을 매칭 받으세요.
programmers.co.kr
def solution(sizes):
temp = []
for i, j in sizes:
if i >= j :
temp.append([j,i])
else:
temp.append([i,j])
wi, hi = sorted(temp, reverse=True), sorted(temp, key=lambda x:x[1], reverse=True)
return wi[0][0] * hi[0][1]https://school.programmers.co.kr/learn/courses/30/lessons/42840
프로그래머스
코드 중심의 개발자 채용. 스택 기반의 포지션 매칭. 프로그래머스의 개발자 맞춤형 프로필을 등록하고, 나와 기술 궁합이 잘 맞는 기업들을 매칭 받으세요.
programmers.co.kr
n1 = [1, 2, 3, 4, 5] * 2000
n2 = [2, 1, 2, 3, 2, 4, 2, 5] * 1250
n3 = [3, 3, 1, 1, 2, 2, 4, 4, 5, 5] * 1000
def solution(answers):
c1,c2,c3 = 0,0,0
for i1,i2,i3,ans in zip(n1, n2, n3, answers):
if i1 == ans: c1 += 1
if i2 == ans: c2 += 1
if i3 == ans: c3 += 1
result = [c1,c2,c3]
maxi = max(result)
answer = []
for i, j in enumerate(result):
if maxi == j:
answer.append(i+1)
return answer깔끔한 예시 정답코드
def solution(answers):
pattern1 = [1,2,3,4,5]
pattern2 = [2,1,2,3,2,4,2,5]
pattern3 = [3,3,1,1,2,2,4,4,5,5]
score = [0, 0, 0]
result = []
for idx, answer in enumerate(answers):
if answer == pattern1[idx%len(pattern1)]:
score[0] += 1
if answer == pattern2[idx%len(pattern2)]:
score[1] += 1
if answer == pattern3[idx%len(pattern3)]:
score[2] += 1
for idx, s in enumerate(score):
if s == max(score):
result.append(idx+1)
return result- score 하나로 변수 3개 쓸필요가 없다는 점
- " if answer == pattern1[idx%len(pattern1)]" 이유는
- pattern 들마다 순환주기가 다르니까 각각 순환주기로 나눠준것
- 7%4 -> 나머지 3이지만
- 1 % 5 -> 1, 2%5 -> 2, 3%5 -> 3, 4%5 -> 4, 5%5 -> 0 이렇게 남는다
- 이를 통해 내가 직전에 짠 코드처럼 *1000 이렇게 할필요가 없어짐
https://school.programmers.co.kr/learn/courses/30/lessons/42839
프로그래머스
코드 중심의 개발자 채용. 스택 기반의 포지션 매칭. 프로그래머스의 개발자 맞춤형 프로필을 등록하고, 나와 기술 궁합이 잘 맞는 기업들을 매칭 받으세요.
programmers.co.kr
- 순열 문제
- "".join(i) -> 튜플과 리스트를 일반 문자열 또는 숫자형태로 변환 무조건 외워야됨!
- 두번 째 "from itertools import permutaions" 라이브러리 또한 순열을 위해서 외워야됨
- 순열의 조합 찾음 -> 소수 찾기
from itertools import permutations
def permutation(x):
# 1보다 큰 자연수 중에서 1과 자기 자신을 제외한 자연수로 나누어떨어지지 않는 자연수
if x < 2: # 연산속도 줄이기 위함?!
return False
else:
for tt in range(2, x):
if x % tt == 0:
return False
return True
def solution(numbers):
count = 0
test_case =[]
for i in range(len(numbers)):
data = list(permutations(numbers, i+1)) # 1자리수 2자리수 전부 조합
rdata = list(set(map("".join, data))) # 중복제거 및, 튜플에서 리스트 형태 변환
for j in rdata: # 개별로 리스트에 정수로 추가
test_case.append(int(j))
test_case = list(set(test_case)) # 재중복 체크
for t in test_case: # 개별적으로 소수인지 아닌지 체크
if permutation(t) == True:
count += 1 # 소수면 count+=1
return count
https://school.programmers.co.kr/learn/courses/30/lessons/42842
프로그래머스
코드 중심의 개발자 채용. 스택 기반의 포지션 매칭. 프로그래머스의 개발자 맞춤형 프로필을 등록하고, 나와 기술 궁합이 잘 맞는 기업들을 매칭 받으세요.
programmers.co.kr
어떤 수를 나누어떨어지게 하는 수를 그 수의 약수라고 합니다.
8을 1, 2, 4, 8,로 나누면 나누어떨어집니다.
1, 2, 4, 8은 8의 약수입니다.
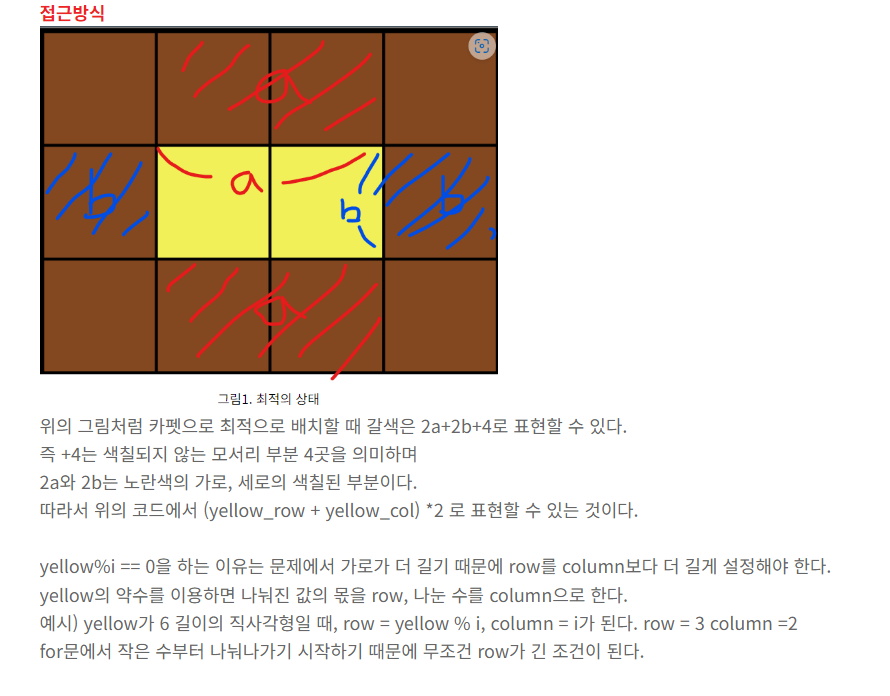
[프로그래머스][Python] 카펫
1. 문제설명 Leo는 카펫을 사러 갔다가 아래 그림과 같이 중앙에는 노란색으로 칠해져 있고 테두리 1줄은 갈색으로 칠해져 있는 격자 모양 카펫을 봤습니다. Leo는 집으로 돌아와서 아까 본 카펫의
siloam72761.tistory.com
def solution(brown, yellow):
answer = []
# 10, 2
for i in range(1,yellow+1): # 3 -> 0,1,2
#yellow의 약수를 이용해 row를 더 길게 설정한다.
if(yellow % i ==0): # i가 2일 때
yellow_row = (yellow /i) # 1.0
yellow_col = i # 2
if (2 * (yellow_row + yellow_col) + 4 == brown): # (2 * (1.0 + 2) + 4 == 10)
return [yellow_row +2, yellow_col+2]https://school.programmers.co.kr/learn/courses/30/lessons/87946
프로그래머스
코드 중심의 개발자 채용. 스택 기반의 포지션 매칭. 프로그래머스의 개발자 맞춤형 프로필을 등록하고, 나와 기술 궁합이 잘 맞는 기업들을 매칭 받으세요.
programmers.co.kr
from itertools import permutations
def solution(k, dungeons):
answer = 0
for permute in permutations(dungeons, len(dungeons)):
count = 0
hp = k
for pm0, pm1 in permute:
if hp >= pm0:
count += 1
hp -= pm1
answer = max(count, answer)
return answer'CoTe > [programmers]1' 카테고리의 다른 글
| 코딩테스트 고득점 Kit (정렬출제) 빈도 높음 평균 점수 높음 (0) | 2024.04.05 |
|---|---|
| [코딩테스트 고득점 Kit] <해시>출제 빈도 높음 평균 점수 보통Key-value쌍으로 데이터를 빠르게 찾아보세요. (0) | 2024.04.04 |
| 올바른 괄호 (0) | 2024.02.02 |
| 기능개발(pop) (0) | 2024.02.02 |
| 큐같은 숫자는 싫어(스택, 큐) (0) | 2024.01.31 |