https://school.programmers.co.kr/learn/courses/30/lessons/1845.
프로그래머스
코드 중심의 개발자 채용. 스택 기반의 포지션 매칭. 프로그래머스의 개발자 맞춤형 프로필을 등록하고, 나와 기술 궁합이 잘 맞는 기업들을 매칭 받으세요.
programmers.co.kr
# my -> pass
from collections import deque
def solution(nums):
q = deque(nums)
result = []
while len(q) != 0:
data = q.popleft()
if data in result:
continue
else:
result.append(data)
if len(result) >= len(nums) //2:
return len(nums) //2
else:
return len(result)# 다른 사람이 짠거
# set을 사용하면 자동으로 줄여주니까
def solution(ls):
return min(len(ls)/2, len(set(ls)))https://school.programmers.co.kr/learn/courses/30/lessons/42576
프로그래머스
코드 중심의 개발자 채용. 스택 기반의 포지션 매칭. 프로그래머스의 개발자 맞춤형 프로필을 등록하고, 나와 기술 궁합이 잘 맞는 기업들을 매칭 받으세요.
programmers.co.kr
# 출력문 문제로 작동이 안됨;
from collections import deque
def solution(participant, completion):
p, c = deque(participant), deque(completion)
has = {}
# while len(p) != 0:
for i in range(len(p)):
player = p.popleft()
if player in c:
c.remove(player)
else:
p.append(player)
s = list(p)
has[1] = s[0]
print(has.values())def solution(participant, completion):
participant.sort()
completion.sort()
print(participant, completion)
for i, j in zip(participant, completion):
if i != j:
return i
return participant[-1]- "return participant[-1]" 하는 이유

- 만일 순차적으로 전부 다 확인했는데 뒤에 complection 기준으로 끝나면 participant의 마지막 사람이 들어온 사람이기 떄문.
# 이게 문제 출제의 의도인 것 같음
def solution(participant, completion):
data = {}
h_val = 0
for i in participant:
data[hash(i)] = i
h_val += hash(i)
for j in completion:
h_val -= hash(j)
return data[h_val]- 해시 함수는 임의의 값을 고정된 길이의 데이터로 변환하는 함수임.
- 즉 딕셔너리를 생성 및 변환된 해시의 값을 알기위한 h_val 생성 -> data, h_Val
- 처음 참가자들을 확인하면서 딕셔너리에 각각의 해시값을 입력함. -> data[hash(i)] = i
- 완주자와 비교하기 위해 h_val에 추가한 해시값을 전부다 sum함
- 이후 완주자(complection)의 값에 해시값을 하나씩 뺴주면서 마지막에 남은 h_val의 해시값을 기존에 추가하였던 data 딕셔너리에서 불러옴

https://school.programmers.co.kr/learn/courses/30/lessons/42577
프로그래머스
코드 중심의 개발자 채용. 스택 기반의 포지션 매칭. 프로그래머스의 개발자 맞춤형 프로필을 등록하고, 나와 기술 궁합이 잘 맞는 기업들을 매칭 받으세요.
programmers.co.kr
# startswith
def solution(phone_book):
phone_book.sort()
for i, j in zip(phone_book, phone_book[1:]):
if j.startswith(i):
return False
return True- 정렬하고 start Swith 함수를 사용한다 -> 앞 뒤랑 비교를 하는데 만일 뒤에 문자 기준으로 j.starswith(i)를 사용하면 문자 시작이 i 기준으로 시작했을 때 True로 반환하므로 False로 처리
# 해시를 사용한 문제
def solution(phone_book):
phone_book.sort()
answer = True
dic = {}
for i in phone_book:
dic[i] = 1
for j in phone_book:
temp = ""
for nums in j:
temp += nums
print(dic, temp, j)
if temp in dic and temp != j:
return False
return answer- 처음 딕셔너리에 전부 다 추가-> dic = {}
- 이후에 폰북에서 하나씩 전화번호를 꺼내고 이후 꺼낸 전화번호를 하나씩 비교하기 시작함
- "temp" 라는 값에 번호를 개별적으로 대입하고 이 때 현재 딕셔너리에 존재하는지를 비교함
- 즉 "if temp in dic"
- 또한 위에 상태로 두면 자기 자신의 번호랑 비교하므로 조건을 추가함
- "and temp != j"
- "if temp in c and temp != j"
- "temp" 라는 값에 번호를 개별적으로 대입하고 이 때 현재 딕셔너리에 존재하는지를 비교함
https://school.programmers.co.kr/learn/courses/30/lessons/42578
프로그래머스
코드 중심의 개발자 채용. 스택 기반의 포지션 매칭. 프로그래머스의 개발자 맞춤형 프로필을 등록하고, 나와 기술 궁합이 잘 맞는 기업들을 매칭 받으세요.
programmers.co.kr
# 해시를 사용한 정석적인 문제
def solution(clothes):
dic = {}
for _, t in clothes:
if t not in dic:
dic[t] = 2
else:
dic[t] += 1
cnt = 1
for i in dic.values():
cnt *= i
return cnt -1- 처음에 딕셔너리 값에 전부 저장함. # int는 저장되는데 str은 저장 안됨
- "dic[t] = 2"를 해준이유는 이후 확률 계산을 할 때 (본인 입었을 때, 안입었을 때)를 위해서 미리 2를함
- 위처럼 아니면 "dic[t] = 1"로 두고 아래서 "cnt *= i+1" 해도 상관은 없음
- 이후 values 값만 불러와서 확률 계산
- ex) 3 * 2
- 이 때 마지막 리턴 값은 -1을 해줌.
- "dic[t] = 2"를 해준이유는 이후 확률 계산을 할 때 (본인 입었을 때, 안입었을 때)를 위해서 미리 2를함
https://school.programmers.co.kr/learn/courses/30/lessons/42579
프로그래머스
코드 중심의 개발자 채용. 스택 기반의 포지션 매칭. 프로그래머스의 개발자 맞춤형 프로필을 등록하고, 나와 기술 궁합이 잘 맞는 기업들을 매칭 받으세요.
programmers.co.kr
문제 설명
스트리밍 사이트에서 장르 별로 가장 많이 재생된 노래를 두 개씩 모아 베스트 앨범을 출시하려 합니다. 노래는 고유 번호로 구분하며, 노래를 수록하는 기준은 다음과 같습니다.
- 속한 노래가 많이 재생된 장르를 먼저 수록합니다.
- 장르 내에서 많이 재생된 노래를 먼저 수록합니다.
- 장르 내에서 재생 횟수가 같은 노래 중에서는 고유 번호가 낮은 노래를 먼저 수록합니다.
노래의 장르를 나타내는 문자열 배열 genres와 노래별 재생 횟수를 나타내는 정수 배열 plays가 주어질 때, 베스트 앨범에 들어갈 노래의 고유 번호를 순서대로 return 하도록 solution 함수를 완성하세요.
제한사항- genres[i]는 고유번호가 i인 노래의 장르입니다.
- plays[i]는 고유번호가 i인 노래가 재생된 횟수입니다.
- genres와 plays의 길이는 같으며, 이는 1 이상 10,000 이하입니다.
- 장르 종류는 100개 미만입니다.
- 장르에 속한 곡이 하나라면, 하나의 곡만 선택합니다.
- 모든 장르는 재생된 횟수가 다릅니다.
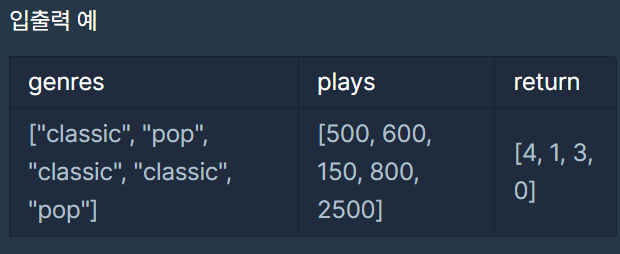
classic 장르는 1,450회 재생되었으며, classic 노래는 다음과 같습니다.
- 고유 번호 3: 800회 재생
- 고유 번호 0: 500회 재생
- 고유 번호 2: 150회 재생
pop 장르는 3,100회 재생되었으며, pop 노래는 다음과 같습니다.
- 고유 번호 4: 2,500회 재생
- 고유 번호 1: 600회 재생
따라서 pop 장르의 [4, 1]번 노래를 먼저, classic 장르의 [3, 0]번 노래를 그다음에 수록합니다.
- 장르 별로 가장 많이 재생된 노래를 최대 두 개까지 모아 베스트 앨범을 출시하므로 2번 노래는 수록되지 않습니다.
※ 공지 - 2019년 2월 28일 테스트케이스가 추가되었습니다.
def solution(genres, plays):
answer = []
dic1 = {} # 가장 많이 재생된 장르
dic2 = {} # 장르 내 많이 재생된 노래 수록
for i, (g,p) in enumerate(zip(genres, plays)):
if g not in dic2:
dic2[g] = p
else: dic2[g] += p
if g not in dic1:
dic1[g] = [(i,p)] # 리스트로 선언해줘야함
else:
dic1[g].append((i,p))
s_dic2 = sorted(dic2.items(), key=lambda x:x[1], reverse = True)
for k,_ in s_dic2: # 순차적으로 확인하는 거임 pop -> classic
s_dic1 = sorted(dic1[k], key=lambda x:x[1], reverse = True)[:2]
for i,_ in s_dic1:
answer.append(i)
return answer- 개인적인 생각으로는 구현문제에 가까움
- 처음 dic1, dic2 생성 -> 가장 많이 재생된 장르, 장르 내 가장 많이 재생된 고유번호
- dic1, dic2
- for i, (g,p) in enumerate(zip(genres, plays)):
- # 가장 많이 재생된 장르
- if g not in dic1:
- dic1[g] =1
- else:
- dic1[g] +=1
- # 장르 내 가장 많이 재생된 고유번호
- if g not in dic2:
- dic2[g] = [i, p] -> 여기서 핵심은 리스트를 사용해줘야 튜플형태로 추가가 가능함
- else:
- dic2[g].append((i,p))
- for i, (g,p) in enumerate(zip(genres, plays)):

- 이후에는 가장 많이 재생된 장르를 찾기위해 정렬을 해줌. -> 횟수 기준으로
- s_dic1 = sorted(dic1.items(), key=lambda x:x[1], reverse = True)

- for i, _ in s_dic1: -> 장르 내 가장 많이 재생된 고유번호도 찾기위해 반복문 사용 -> 또한 반복문을 통해 가장 재생이 많이 된 순서로 진행할 수 있음
- s_dic2 = sorted(dic2[i], key=lambda, reverse=True)[:2] -> 현재 dic2는 각 장르마다 리스트로 생성되어 있음. 따라서 그 리스트를 두번 째 재생횟수 기준으로 재정렬함
- 여기서 "[:2]"를 해주는 이유는 문제에서 각 장르별 최대 2개씩을원 했으므로 만약 하지 않는다면

"[:2]" 입력 이후

- for k, _ in s_dic2:
- anwer.append(k)
'CoTe > [programmers]1' 카테고리의 다른 글
| [완전탐색] 빈도 높음 평균 점수 낮음 -> "".join(i) 무조건 외우자 (0) | 2024.04.09 |
|---|---|
| 코딩테스트 고득점 Kit (정렬출제) 빈도 높음 평균 점수 높음 (0) | 2024.04.05 |
| 올바른 괄호 (0) | 2024.02.02 |
| 기능개발(pop) (0) | 2024.02.02 |
| 큐같은 숫자는 싫어(스택, 큐) (0) | 2024.01.31 |