A Real-Time Apple Targets Detection Method for Picking RobotBased on Improved YOLOv5
기존 사과 감지 알고리즘에서는 다른 사과에 가려진 사과를 구분하지 못했다.
이러한 실용적인 문제를 해결하기 위해 개선하였다.
1. BottleneckCSP 모듈을 BottleneckCSP-2 모듈로 개선됨
2. SE모듈 Visual Attention Mechanism 네트워크에 속해 있던 이 네트워크는 제안된 개선된 백본 네트 워크 삽입
3. 기존 YOLOv5s 네트워크에서 중간 크기의 타겟 탐지 레이어에 입력되는 특징 맵의 결합 융합모드가 개선됨.
4. 원래 네트워크의 초기 앵커 박스 크기가 개선됨.
YOLOv5 구조 설명
본 연구에서는 두 가지 종류의 대상을 식별하고 인식 모델은 실시간 성능과 경량 속성에 대한 요구 사항이 높기 때문에.
인식 모델의 정확도, 효율성 및 크기를 종합적으로 고려하엿고, YOLOv5s 모델을 기반으로 인식 네트워크의 개선된 설계를 수행.

YOLOv5s 프레임워크는 백본, 넥, 헤드 로 구성됨.
백본
- 백본: 다양한 세분화된 이미지를 집계하고 이미지 기능을 형성하는 컨볼루션 신경망.
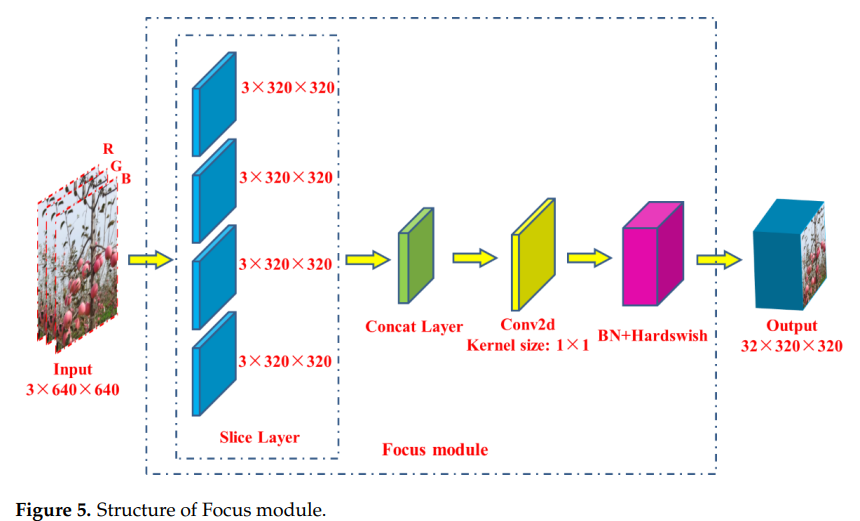
- 백본 네트워크의 첫 번째 계층은 모델 계산을 줄이고 교육 속도를 가속화하도록 설계된 포커스 모듈이다.
- 포커스 모듈의 기능:
- 1. 입력 3채널 이미지(YOLOv5s의 기본 입력 이미지 크기 아키텍처는 3 × 640 × 640) 슬라이스 작업을 사용하여 슬라이스당 3 × 320 × 320 크기의 4개의 슬라이스로 분할
- 2. concat 연산을 이용하여 4개의 섹션을 깊이 연결하여 출력 feature map의 크기는 12 × 320 × 320이고, 32개의 convolution kernel로 구성된 convolutional layer를 통해 32 × 크기의 output feature map을 생성한다. (320 × 320이 생성됨)
- 3. BN 계층(batch normalization)과 Hardswish 활성화 함수를 통해 결과를 다음 계층으로 출력.
- 포커스 모듈의 기능:
- 백본 네트워크의 첫 번째 계층은 모델 계산을 줄이고 교육 속도를 가속화하도록 설계된 포커스 모듈이다.
- 2번 째 계층은 Conv 연산
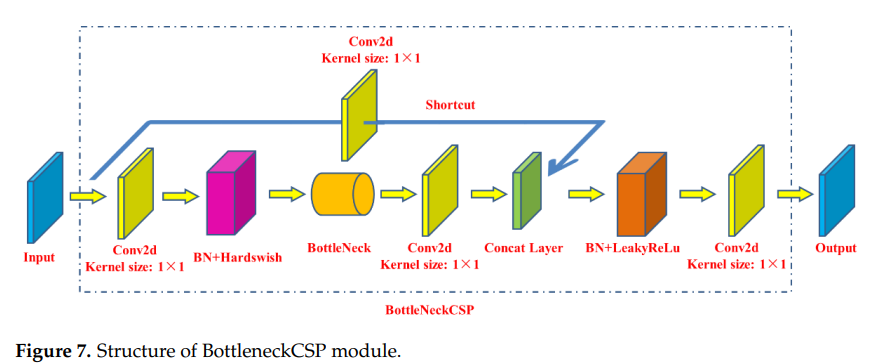
- 백본 네트워크의 세 번째 계층은 BottleneckCSP 모듈
- 이미지의 깊은 특징을 더 잘 추출하도록 설계됨.
- BottleneckCSP 모듈은 주로 Bottleneck 모듈로 구성되며, 이는 Conv 커널 크기가 1 × 1인 convolutional layer(Conv2d + BN + Hardswish 활성화 함수)와 convolution kernel 크기가 3인 convolutional layer를 연결하는 residual 네트워크 아키텍처
- × 3. Bottleneck 모듈의 최종 출력은 이 부분의 출력과 residual구조를 통한 초기 입력을 더한 것

- BottleneckCSP 모듈( 그림 7 )의 초기 입력은 2개의 분기(branch)로 입력되고, 2개의 분기(branches)에서 컨볼루션 연산을 통해 피처 맵의 채널 수가 절반으로 줄어든다.
- 다음 2번 브랜치의 Bottleneck 모듈과 Conv2d 레이어를 통해 1번 브랜치와 2번 브랜치의 출력 feature map을 깊이 연결하여 concat 연산을 활용
- 마지막으로 BN 계층과 Conv2d 계층을 차례로 거쳐 모듈의 출력 특징 맵을 얻었고 이 특징 맵의 크기는 BottleneckCSP 모듈의 입력 크기와 동일해진다.
- 백본 네트워크의 아홉 번째 계층은 SPP 모듈(공간 피라미드 풀링)( 그림 8 )으로, 모든 크기의 특징 맵을 고정 크기의 특징 벡터로 변환하여 네트워크의 수용 필드를 개선하도록 설계
- YOLOv5s에 속한 SPP 모듈의 입력 피처 맵 크기는 512 × 20 × 20이다. 먼저, 256 × 20 × 20 크기의 피처 맵이 컨볼루션 레이어를 통과한 후 출력
- convolution kernel size는 1 × 1이다. 그러면 이 feature map과 3개의 병렬 Maxpooling layer(maximum pooling layer)를 통해 subsampling된 output feature map을 깊이 연결
- output feature map의 크기는 1024 × 20 × 20. 마지막으로 512 x 20 x 20 크기의 최종 출력 특징 맵은 512 컨볼루션 커널로 컨볼루션 레이어를 통과한 후 얻는다.
- YOLOv5s에 속한 SPP 모듈의 입력 피처 맵 크기는 512 × 20 × 20이다. 먼저, 256 × 20 × 20 크기의 피처 맵이 컨볼루션 레이어를 통과한 후 출력

넥
- FPN(feature 피라미드 네트워크)을 생성하는 데 주로 사용되는 혼합 및 결합된 이미지 특징의 일련의 특징 집합 레이어이며 출력 특징 맵은 감지 네트워크(예측 네트워크)로 전송 현재는 PAnet 사용
- 이 네트워크의 특징 추출기는 Since the feature 를 향상시키는 새로운 FPN 구조를 채택하기 때문에 low-level features의 전송이 향상되고 스케일이 다른 물체의 감지가 향상
헤드
- detect 네트워크는 모델의 최종 감지 부분에 주로 사용(여기서 감지 네트워크는 헤드를 뜻함)
- 이전 계층에서 출력된 피처 맵에 앵커 박스를 적용하고 대상 객체의 범주 확률, 객체 점수 및 위치가 포함된 벡터를 출력
- detection network of YOLOv5s는 서로 다른 크기의 이미지 객체를 감지하는 데 사용되는 각각 80 × 80, 40 × 40 및 20 × 20 차원의 특징 맵을 입력으로 하는 3개의 탐지 레이어로 구성
- 각 감지 레이어는 최종적으로 21채널 벡터((2개의 클래스 + 1개의 클래스 확률 + 4개의 주변 상자 위치 좌표) × 3개의 앵커 상자)를 출력한 다음 원본 이미지에서 예측된 경계 상자와 대상의 범주를 생성하고 레이블을 지정
네트워크 개선
2.2.2벡본 네트워크 개선
- 하드웨어 장치에 쉽게 배포할 수 있도록 모델의 크기도 최대한 압축해야 한다.
- 탐지 정확도를 보장한다는 전제 하에 네트워크 가중치 매개변수의 양과 부피를 줄여 사과 따기 로봇을 위한 과일 표적 인식 네트워크의 경량화 및 개선된 설계를 실현
- YOLOv5s 아키텍처의 백본 네트워크에는 4개의 BottleneckCSP 모듈이 포함되어 있으며, 여기에는 섹션 2.2.1 에 따라 다중 컨볼루션 계층이 포함 되어있다.
- 컨볼루션 연산은 이미지의 특징을 추출할 수 있지만 컨볼루션 커널은 많은 수의 매개변수를 포함하므로 인식 모델에서 많은 수의 매개변수가 발생한다.
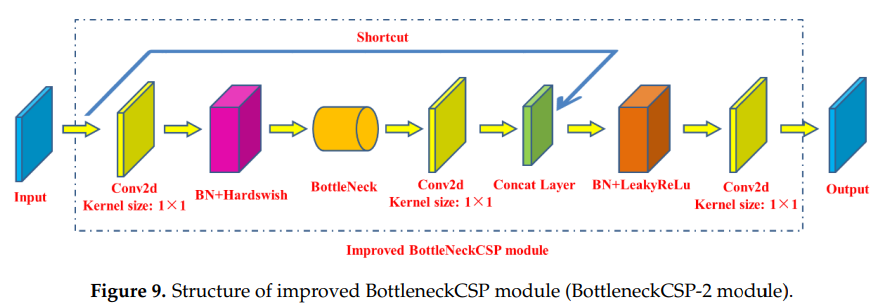
- 원본 모듈의 브리지 브랜치(2갈래 나눠저 있는 것)에 있는 컨볼루션 레이어를 제거하고 BottleneckCSP 모듈의 입력 특성 맵을 다른 브랜치의 출력 특성 맵과 깊이 직접 연결하여 모듈의 매개변수 수를 효과적으로 줄였습니다.
- BottleneckCSP-2의 경량화 특성으로 인해 영상의 깊은 특징 추출에 부족함을 유발할 수 있는 한계를 보완하기 위해 BottleneckCSP 모듈이 사용되었던 기존 백본 네트워크의 4개 부분을 연구에서 4개의 동일한 BottlencekCSP-2 모듈로 대체하였다.
2.2.3. Fusion Feature Layer 개선
- 다양한 축척의 feature맵을 융합하는 것은 표적 탐지 네트워크의 인식 성능을 향상시키는 중요한 방법.
- 특징 융합의 목적은 이미지에서 추출한 특징을 입력 특징보다 더 판별력이 있는 특징으로 결합하는 것
- low-level feature map 더 높은 해상도를 가지며 대상 개체에 대한 더 많은 위치와 자세한 정보를 포함한다.
- 그러나 컨볼루션 레이어를 통한 피처 추출이 적기 때문에 low-level feature 맵의 의미가 낮고 피처 맵에 더 많은 노이즈가 포함됨
- High-level feature map 의미 정보는 풍부하지만 피처 맵 해상도가 낮고 이미지의 세부 사항에 대한 인식 능력이 상대적으로 부족
- 섹션 2.2.2 의 원래 YOLOv5s 아키텍처 백본에 대한 경량 개선 설계를 기반으로 한다.
- 개선된 네트워크 아키텍처의 레이어에서 출력된 피처 맵의 차원과 결합하여 원래 YOLOv5s 아키텍처의 레이어 4와 15, 6과 11, 10과 21의 융합이 레이어 5와 18, 8의 융합으로 변경.이 연구에서 설계된 네트워크 아키텍처의 14, 13, 24입니다.
- 현재 사과나무의 사과 타겟의 크기가 대부분 중간 크기에 속해있다.
- 연구에서 개선된 설계 네트워크 아키텍처의 23번째 계층의 출력 특징 맵으로 인해 중간 크기 개체에 대한 대상 탐지 계층의 입력 특징 맵으로 사용되므로 사과 탐지의 정확도를 높이기 위해 구성.
- High-level 피처의 저해상도로 인한 공간 정보 손실, 기존 YOLOv5s 아키텍처에서 중형 타겟 탐지 레이어에 입력되는 특징 맵의 브리지 융합(14번째 레이어와 18번째 레이어의 특징 융합)을 개선하고 최적화했으며 특징 추출 레이어의 출력은 하위 레이어의 더 큰 인식 필드는 중간 크기의 타겟 탐지 레이어보다 먼저 위치한 특징 추출 레이어의 출력과 융합되었다.
- 즉, 개선된 설계 네트워크의 14번째 레이어와 21번째 레이어의 출력 특성 맵이 융합됨.
-
- 사과 따기 로봇을 위한 개선된 디자인의 경량 과일 인식 네트워크의 아키텍처는 다음과 같다.
- 하위 레이어에서 더 큰 인식 필드를 가진 특징 추출 레이어의 출력이 중간 크기의 타겟 탐지 레이어 앞에 위치한 특징 추출 레이어의 출력과 융합되었다.
- 즉, 개선된 설계 네트워크의 14번째 레이어와 21번째 레이어의 출력 특성 맵이 융합
- 사과 따기 로봇을 위한 개선된 디자인의 경량 과일 인식 네트워크의 아키텍처는 다음과 같다.

2.2.4. 초기 앵커 박스 크기 개선
3가지 크기의 원본 YOLOv5s 프레임워크의 초기 감지 앵커 박스는 <10 × 13>, <16 × 30>, <33 × 23>인 3가지 크기(80 × 80, 40 × 40, 20 × 20)의 각 피처 맵에 대해 설정된다.
- <30 × 61>, <62 × 45>, <59 × 119>; 각각 <116 × 90>, <156 × 198>, <373 × 326>이고 3개의 피처 맵은 각각 소형, 중형 및 대형 물체의 감지에 사용되는 다중 스케일 감지 계층에 입력됩니다. 하지만, 배경의 멀리 떨어진 심기 줄의 나무 위 사과와 사과 따기 로봇 사이의 거리가 너무 멀기 때문에 그 사과는 효과적인 따기 대상으로 볼 수 없다. 이미지의 배경에 있는 작은 사과의 잘못된 인식을 방지하고 전경에 있는 사과의 크기 분석을 기반으로 전경에 있는 사과의 식별 정확도를 향상시키기 위해 배경에 있는 작은 사과의 크기 원본 YOLOv5s 네트워크에서 중소 규모의 대상 탐지 계층에 속하는 초기 앵커 박스의 크기 및 이미지 크기가 개선되었습니다. 이미지에서 사과 타겟의 길이-너비 비율을 결합하여 초기 앵커 박스의 길이-너비 비율을 약 1/1로 설정하고 <80 × 70>, <75 × 75>, <85 × 100>으로 수정했습니다. <95 × 110>, <130 × 110>, <115 × 125>로 사과 표적을 정확하게 식별합니다.
2.3. 네트워크 교육
- 연구에서 개선된 YOLOv5s 네트워크는 종단 간 방식으로 SGD(stochastic gradient descent)에 의해 훈련. 모델 훈련의 배치 크기는 4로 설정되었으며 매번 모델의 가중치를 업데이트하기 위해 BN 계층에서 정규화를 수행. 모멘텀 팩터(momentum)는 0.937, 무게감쇠율(decay)은 0.0005로 설정하였다. 초기 벡터와 IOU(intersection over union) 임계값을 모두 0.01로 설정하고 색상(H), 채도(S) 및 밝기(V)의 향상 계수를 각각 0.015, 0.7 및 0.4로 설정했습니다. 훈련 epoch의 수는 300으로 설정
- 훈련 후 획득한 인식 모델의 가중치 파일을 저장하고, 테스트 세트를 활용하여 모델의 성능을 평가
2.3.2. 교육 결과
- 훈련 손실과 검증 손실 곡선은 그림 11a 에 함께 표시되어 있으며 네트워크 훈련의 처음 100 epoch에서 손실 값이 급격히 감소
- 기본적으로 250 epoch 훈련 후에는 안정적인 경향
- 따라서 본 연구에서는 사과 따기 로봇의 과일 표적 인식 모델로 300 epoch 훈련 후의 모델 출력을 결정
- 훈련 세트 mAP(평균 평균 정밀도)와 검증 세트 mAP가 그림 11b 에 함께 표시

2.4.1. 모델 평가지표

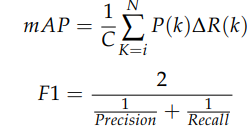
- TP 는 사과 표적의 두 품종이 정확하게 식별된 수
- FP 는 사과 대상으로 잘못 식별된 배경의 수