일반화(generalization): 학습 데이터와 input data가 달라져도 출력에 대한 성능 차이가 나지 않게 하는 것을 일반화라고 한다.다른 외부의 data를 넣어도 Trainning data로 모델을 학습한 것과 비슷한 결과를 얻는 것을 말합니다
최적화(Optimization): 최적화는 신경만 분야에서 손실함수의 값을 최소화하는 하이퍼 파라미터(Hyper Parameter)의 값을 찾는 것을 말합니다. 여기서 하이퍼 파라미터(Hyper Parameter)는 사용자가 직접 정의할 수 있는 Parameter를 말하는데, 쉽게 말해서, 사람이 파라미터 값을 조절할 수 있는 것들을 말합니다. 예를 들어서, batch-size라던지 아니면 Learning-rate 라던지 등 모델에 관한 사용자가 조절할 수 있는 파라미터를 말합니다. 이와 관련하여, 최적화와 하이퍼 파라미터를 조절하는 최적화 방법은 대표적으로 확률적 경사하강법(Stochastic Gradient Descent, SGD)가 있습니다. SGD는 경사하강법에 관하여 이해를 하면 됩니다. 2차 함수가 있을 때, Learning-rate(lr)이 작으면 하강하는 속도가 느려져 학습을 시키는데 시간이 많이 걸리고, lr이 너무 크면 하강하는 폭이 커져서 결국엔 학습이 발산적으로 이루어집니다. 그래서, 적절한 lr을 줘야 합니다. 여기서, lr은 위에서 설명했던 하이퍼 파라미터입니다.
Localization : Localization이란 [1] 이미지의 두번째 경우 같이 모델이 주어진 이미지 안의 Object 가 이미지 안의 어느 위치에 있는지 위치 정보를 출력해주는 것으로, 주로 Bounding box 를 많이 사용하며 bounding box 의 네 꼭지점 pixel 좌표가 출력되는 것이 아닌 left top, 혹은 right bottom (x, y, w, h)좌표를 출력한다.
Prunning은 대형 모델에서 중복 연결을 제거한다. 하지만 실질적인 속도 향상을 위해 전용 하드웨어 또는 소프트웨어 사용자 지정이 필요할 수 있다.compact를 직접 학습할 수 있는 좋은 방법은 지식증류이다.
지식 증류와 유사하게 힌트 학습[32]은 교사 모델과 학생 모델의 전체 상위 수준 기능의 불일치를 최소화하여 학생 모델을 개선합니다. 그러나 탐지 모델에 힌트 학습을 직접 적용하면 성능이 저하된다는 것을 알았다 그 이유는 dectors가ground truth object 와 겹치는 local region에 관심을 기울이는 반면 classfication 모델은 global context에 더 많은 관심을 기울인다. 따라서 전체 기능 모방을 직접 수행하면 특히 배경 인스턴스가 압도적이고 다양한 개체 감지의 경우 관심 없는 영역에서 많은 양의 노이즈가 불가피하게 발생한다.
detectors는 local object regions에 더 관심을 갖기 대문에 discrepancy of features response는 복잡한 detection model이 객체 instance를 감지하는 방법에 대한 중요한 정보를 전달한다. 이 위치 간 불일치를 활용하여 지식을 증류하는 것을 목표로 한다.
Figure1.과 같이 near object anchor location에서 유익한 정보를 효과적으로 추정하기 위해 ground true bounding box와 anchor priors(anchor boxs)를 활용하는 새로운 메커니즘을 개발하고 학생 모델이 해당 위치에서 교사를 모방하도록 한다.
이 방법을 세분화된 기능이라고 합니다.
2. Related Works
○ Object detection
실시간 추론의 요구 사항에 따라 1단계 검출기[29, 24]가 제안 우리는 부분적으로 모바일 장치에 구현하기 위해 경량 감지기를 설계
○knowledge ditillation
detection head에 전체 기능 모방과 특정 증류 손실을 모두 추가하려고 시도했지만 전체 기능 모방이 학생 모델의 성능을 저하시키고 증류를 수행할 때 교사와 학생 사이의 지역 제안[11] 불일치를 처리하는 방법이 불분명합니다
○ Model acceleration
정확도를 줄이고 심층 DNN모델의 속도를 높이기 위해 quantization, , prunning, sparsifying(희소화) 사용 하지만 이런 접근 방식은 실질적인 속도 향상을 위해 특정 하듸웨어 또는 소프트웨어 사용자 지정이 필요하다. prunning은 가지치기 비율이 높을 때 이러한 방법은 불가피하게 성능을 크게 저하시킨다.
3. Method
Figure 2. Illustration of the proposed fine-grained feature imitation method. The student detector is trained by both ground truth supervision and imitating teacher’s feature response on close object anchor locations. The feature-adaptation layer makes student’s guided feature layer compatible with the teacher. To identify informative locations, we iteratively calculate IOU map of each groundtruth bounding box with anchor priors, filter and combine candidates, and generate the final imitation mask, ref. to Sec. 3.1 for details.
The student detector는 ground - truth supervision과 Near object anchor location에 대한 교사의 feature reaspones을 imitation 하여 훈련됩니다.feature-adaptation layer는 학생의 guide feature layer를 교사와 호환되도록 합니다. 유익한 위치를 식별하기 위해 앵커 이전이 있는 각 ground truth bounding box의 IOU 맵을 반복적으로 계산하고, 후보를 필터링 및 결합하고, 최종 모방 마스크인 ref를 생성합니다. 초로 자세한 내용은 3.1.
near object anchor loacation에 대한 feature reasponse의 차이가 학습된 지식을 증류할 수 있는 대형detector가 일반화하는 경향에 대한 중요한 정보를 드러낸다는 것입니다. 특히, 객체 인스턴스(물체)에 가까운 fine-grained local feature regions(영역)을 형성하는 앵커 위치를 추정하는 새로운 메커니즘을 제안하고 학생모델이 해당 영역에 대한Hight level feature response of teachr을 모방하여 향상된 성능을 얻도록 합니다. 네트워크를 포함한 다른 모델 가속 방법과 직교합니다. 가지치기와 양자화.
3.1 imitation region estimation
Figure 1
그림 1과 같이near object anchor location는 각 물체에 대한 local feature regions(영역)을 형성한다. local feature region을 공식적으로 정의하고 연구하기 위해 우리는 ground truth bounding box와 anchor priors(anchor boxs)를 활용하여 해당 영역을 각 독립 이미지에 대한 마스크 I로 계산하고 임계값 ψ에 의해 영역의 크기를 제어합니다. 다음에서 feature map 을 사용하여 [31]에 앵커 우선 순위가 정의된 마지막 feature를 항상 참조한다.
FIgure 2
구체적으로, 그림 2와 같이 각 ground truth box에 대해 W × H × K IOU 맵 m을 형성하는 모든 앵커와 IOU를 계산합니다. 여기서 W와 H는 feature map의 너비와 높이를 나타내고 K는 K개의 미리 설정된 anchor box를 나타냅니다. 그런 다음 가장 큰 IOU 값 M = max(m)에 임계값 인수 ψ를 곱하여 필터 임계값 F = ψ * M을 얻습니다. F를 사용하면 IOU 맵을 필터링하여 F보다 큰 위치를 유지하고 OR 연산과 결합하여 W × H 마스크를 얻습니다. 모든 GT-box와 mask를 결합하면 최종 fine-grained imataionMask I을 얻습니다.
ψ = 0일 때 생성된 마스크는 feature map의 모든 위치를 포함하지만 ψ =1일 때는 위치가 유지되지 않습니다. ψ를 변경하여 다양한 모조 마스크를 얻을 수 있습니다. 모든 실험에서 상수 ψ = 0.5가 사용됩니다. 자세한 절제 연구에서ψ = 0.5가 최고의 증류 성능을 제공함을 보여줍니다(섹션 4.4.4 참조). IOU 맵을 필터링하기 위해 F의 고정 값을 사용하지 않는 이유는 일반적으로 객체 크기가 넓은 범위에서 변하기 때문입니다. 고정 임계값은 특정 축척 및 비율의 개체에 대해 편향됩니다(4.2절 참조).
3.2. Fine-grained feature imitation
두 가지 이유로 adaptation계층을 추가합니다.
1) 학생 기능의 채널 번호는 교사 모델과 호환되지 않을 수 있습니다. 추가된 레이어는 거리 메트릭을 계산하기 위해 전자를 나중에 정렬할 수 있습니다.
2) 학생과 교사가 호환되는 기능을 가지고 있더라도 학생이 교사의 feature에 근접하도록 강제하면 적응된 상대에 비해 약간의 이득이 직접적으로 발생함을 발견했습니다.
에 대해 교사 detection model's의 지식을 학습하기 위해 다음 목표를 최소화하도록 학생 모델을 훈련합니다.
s:student model의 안내된 feature map
i, j:너비 W와 높이 H의 feature map에서 각 가까운 물체 앵커 위치(i, j)
c: Channel?
I(imitation mask): Imitatin mask
Np(is the number of positive points in the mask: 마스크의 양수 점 수
1. 장난감 탐지기의 모방 결과 및 일부 비교 방법의 결과. 1×는 기본 detector이고, 0.5× 및 0.25×는 기준선 역할을 하는 ground true supervision 으로 훈련된 직접 프루닝된 모델입니다.
-I는 추가로 제안된 imitation loss 있음을 의미하고
-F는 full feature imitation 의미하고 힌튼학습
-G는 직접 크기 조정된 grounda true boxes를 imitation region으로 사용하는 것을 의미 피처 레이어에서 동일한 스트라이드로 ground truth box를 직접 스케일링하고 해당 영역에 모방을 적용하는 매우 간단한 설정(0.25×-G)은 제안된 방법보다 훨씬 적은 이득
-D는 바닐라 증류 손실만 추가하는 것을 의미 바닐라 지식 증류[16]를 감지 설정
-ID는 제안된 imtation loss 과 distillation loss이 모두 부과되는 경우를 나타냅니다.우리는 증류 손실과 모방 손실(0.25-ID로 표시)을 결합하려고 시도하지만 성능은 모방 용어만 사용하는 것보다 나쁩니다. 이는 모델 출력에 대한 높은 수준의 기능 모방 및 증류가 매우 다른 목표
4. Experiments
도로 객체 클래스를 포함하는 KITTI 감지 벤치마크를 사용하여 개발된 경량 장난감 감지기에 대한 실험을 수행 Faster R-CNN 모델에 대한 방법을 추가로 검증
4.1. Lightweight detector
제안된 모방 방법의 성능 향상을 평가하기 위해 수동으로 설계된 경량 검출기를 제시. 이 검출기는 제한된 플롭과 매개변수로 탁월한 분류 성능을 제공하는 셔플렌[39]에 기초. 끔찍한 결과를 낳는다는 것을 발견. 이는 상단 피쳐 맵의 각 점이 32의 동일한 보폭을 가지기 때문에 입력 이미지에서 앵커 박스의 정렬이 매우 거칠어지기 더 작은 보폭으로 낮은 출력 레이어로 이동하는 것 또한 기능이 덜 강력하기 때문에 성능이 좋지 않음. 결함을 해결하기 위해 다음과 같은 리팩터링을 수행하고 검출을 위한 개선된 1단계 Lightweight detector 개발
(1) Conv1의 보폭을 2에서 1로 변경한다. 원래 네트워크 설계는 입력 이미지를 신속하게 다운샘플링하여 계산 비용을 절감한다. 그러나 객체 감지를 위해서는 다운스트림 기능 디코더(디텍터 헤드)가 제대로 작동하려면 고해상도 기능이 필요하다. 이러한 수정은 모든 con의 활용을 가능하게 한다.이러한 수정을 통해 모든 컨볼루션 레이어를 사용할 수 있으며 최상위 기능 맵에 대한 고해상도를 유지합니다.
(2) Conv1의 출력 채널을 24에서 16으로 수정하여 메모리 공간과 계산을 줄입니다.
(3) 3단계의 블록 수를 8에서 6으로 줄입니다. 이러한 수정으로 인해 사전 훈련 정밀도가 약간 낮아지지만 탐지 성능에는 영향을 미치지 않습니다. 전체 런타임이 크게 줄어듭니다.
(4) reg 및 cls 헤드 이전에 처음부터 훈련된 2개의 추가 셔플넷 블록을 추가합니다. 추가된 블록은 탐지를 위한 고급 기능의 추가 적응을 제공합니다.
(5) 우리는 클래스를 구별하는 매우 간단한 RPNalike 검출기를 사용합니다. 이전 레이어와 달리 감지 헤드는 전체 회선을 사용하지만 매개변수가 증가하면 정확도가 크게 향상됩니다. 우리는 다음 섹션에서 1x와 같은 경량 베이스 검출기를 참조합니다. 모델의 아키텍처 다이어그램은 보충 자료를 참조하십시오.
4.2. Imitation with lightweight detectors
먼저 위에서 제시한 장난감 탐지기에 제안한 방법을 적용한다. 우리는 기본 모델을 교사로 사용하고(1×로 표시) 학생 모델에 대해 각 계층의 채널을 직접 절반으로 사용합니다. 구체적으로 말하면, 교사 모델을 반으로 하여 0.5X 모델을 얻고 두 번(75% 채널 제거)하여 0.25X 모델을 얻습니다. 우리는 도전적인 KITTI[8] 데이터셋에 대한 실험을 수행합니다. 테스트 세트 주석을 사용할 수 없기 때문에 [3, 26]에 따라 훈련 데이터 세트를 훈련 세트와 검증 세트로 분할하고 동일한 비디오 시퀀스에서 나온 것이 아닌지 주의 깊게 확인합니다. 검증 세트에서 검출기 성능을 평가하기 위해 공식 평가 도구를 사용합니다. 표 3.2는 전체 모조 결과를 보여줍니다.학생 모델 및 다른 방법과의 비교. 매개변수와 계산의 감소는 항상 기하급수적인 성능 저하를 가져온다는 것은 잘 알려져 있습니다. 예를 들어 0.5X 모델은 교사에 비해 약 4.7mAP만 희생하는 반면 0.25X 반감기는 16.7mAP 하락을 초래합니다(일반적으로 모델만 줄였을 때). 그러한 어려운 경우에 제시된 방법은 여전히 학생 모델에 대해 상당한 부스트를 달성합니다. 즉, 0.5x 모델은 2.5mAP 개선을 얻고 0.25x 모델은 6.6mAP(0.25x-I)로 부스트되며 이는 비 모델의 14.7%입니다(imitation 하였을 때). - 모방한 것. 보행자에 대한 0.5x 모델의 개선은 보행자에 대한 교사와 모방되지 않은 학생 사이의 간격이 작기 때문에 다른 클래스보다 작습니다. 0.25× 모델과 설정을 비교하는 4가지 실험을 수행합니다.표 3.2의 마지막 4줄과 같이. 첫 번째는 힌트 학습[32]입니다(즉, 0.25×-F로 표시되는 전체 기능 모방). 분류에 대해서는 잘 수행되지만 원래 0.25x 모델에 큰 성능 저하(8.9mAP)를 가져옵니다. 배경 잡음이 Sec에서 검증된 교사 모델의 유익한 감독 신호를 압도하기 때문이라고 추측합니다. 4.4.5. 피처 레이어에서 동일한 스트라이드로 ground truth box를 직접 스케일링하고 해당 영역에 모방을 적용하는 매우 간단한 설정(0.25×-G)은 제안된 방법보다 훨씬 적은 이득을 제공합니다. 그 이유는 배경 영역의 노이즈는 피하는 반면 이 방법은 일부 가까운 물체 위치에서 중요한 감독을 놓쳤기 때문입니다.세 번째 설정(0.25×-D)에서 바닐라 지식 증류[16]를 감지 설정에 적용하면 불쾌한 결과(mAP의 0.9만 증가)가 생성되고 Sec.에서 직관을 확인합니다. 1. 마지막으로, 우리는 증류 손실과 모방 손실(0.25-ID로 표시)을 결합하려고 시도하지만 성능은 모방 용어만 사용하는 것보다 나쁩니다. 이는 모델 출력에 대한 높은 수준의 기능 모방 및 증류가 매우 다른 목표를 가지고 있음을 의미합니다.
4.3. Imitation with Faster R-CNN
우리는 세 가지 설정에서 Faster R CNN 모델의 보다 일반적인 아키텍처로 광범위한 실험을 추가로 수행합니다. 1) 반 학생 모델. 2) 얕은 학생 모델. 3) 다층 모방.
Halved student mode
이 설정에서는 Resnet101 기반 Faster R-CNN을 교사 모델로 사용하고 완전 연결 계층을 포함한 각 계층의 채널 수를 절반으로 줄여 학생 모델을 구성합니다. 표 4 및 표 2에 표시된 대로 COCO 및 Pascal VOC07 데이터 세트로 실험을 수행합니다. 전체 교사 모델을 분명히 절반으로 줄이면 성능이 크게 떨어집니다. 모방을 통해 반으로 줄인 학생 모델은 COCO 데이터 세트를 사용하여 Pascal 스타일 평균 정밀도와 COCO 스타일 평균 정밀도 모두에서 2.8 절대 mAP 이득과 같이 상당한 부스트를 얻습니다. Pascal VOC07 데이터 세트에 대한 3.8 절대 mAP 이득. 결과는 우리의 방법이 교사 탐지기의 지식을 반으로 나눈 학생에게 효과적으로 증류할 수 있음을 보여줍니다.
Shallow student network
이 설정을 위해 교사 모델의 계층 채널을 절반으로 줄이는 대신 교사 모델과 유사한 아키텍처를 가진 더 얕은 학생 백본을 선택합니다. 구체적으로, 우리는 학생으로서 VGG11 기반 Faster R-CNN과 교사로서 VGG16 기반의 두 가지 모방 실험을 수행합니다. Resnet50 기반 Faster R-CNN은 학생으로, Resnet101 기반은 교사로 사용됩니다. 표 3에서 볼 수 있듯이 얕은 백본 기반 학생 모델은 모두 상당한 개선을 얻었습니다. 특히 VGG11 기반 학생 모델의 경우 모방된 모델은 mAP에서 8.0 절대 이득을 얻습니다. 우리 방법은 얕은 백본으로 인한 성능 저하의 74%를 거의 복구합니다. 등뼈.
Multi-layer imitation
이전의 모방 실험은 형상 맵의 단일 레이어를 사용한 것으로, 형상 피라미드 네트워크(FPN)의 기본 작업을 사용한 다층 모방으로 실험을 더욱 확장한다[21]. 고속 R-CNN 프레임워크와 결합된 FPN은 앵커 이전 크기가 다른 여러 계층에서 지역 제안을 수행하고, 풀은 ROI 크기에 따라 해당 계층에서 기능을 수행한다. 해당하는 이전 앵커를 사용하여 각 레이어의 모방 영역을 계산하고 학생 모델이 각 레이어의 특징 응답을 모방하도록 한다. 교사 감지 모델은 Resnet50 FPN 기반 고속 R-CNN이며 학생은 절반으로 줄어든 상대 모델이다. 표 5와 같이 모방 학생은 파스칼 스타일 평균 정밀도에서 3.2 mAP, COCO 스타일 평균 정밀도에서 3.6 mAP 이득을 얻습니다.
4.4. Analysis
4.4.1 Visualization of imitation mask
다. 그림 3은 입력 이미지에 크기가 조정되고 오버레이된 모조 마스크의 예를 보여줍니다. 6개의 이미지 중 그림 3(a)는 원본 이미지입니다. 그림 3(b) 3(c) 3(d)는 각각 ψ = 0.2, ψ = 0.5, ψ = 0.8로 생성됩니다. 각 F = 0.5 및 F = 0.8의 일정한 A임계값으로 필터링됩니다. F = 0.5에서만 일부 개체가 누락되었고 F = 0.8에서는 거의 모든 모조 마스크가 사라졌습니다. 이는 비슷한 크기의 정답 상자에 대한 F 바이어스의 필터 임계값이 일정하기 때문
4.4.2 Qualitative performance gain from imitation
결과는 VOC07 데이터 세트에 대한 VGG11 기반 Faster R-CNN 모델에서 가져온 것입
그림 3. 입력 이미지에 오버레이된 계산된 모조 마스크의 예. 실제 마스크는 마지막 기능 맵에서 계산되며 입력 이미지에 표시할 해당 비율로 마스크를 확대합니다. (a) 원본 이미지. (b) ψ = 0.2. (c) ψ = 0.5. (d) ψ = 0.8. (e) 단단한 타작-0.5. (f) 단단한 타작-0.8. Thresh-*는 제안된 접근 방식에 대한 다른 임계값 인자를 나타내고, Hard-thresh-*는 IOU 맵을 필터링할 때 F의 상수 임계값을 사용하는 것을 의미합니다.
더 명확한 시각화를 위해 간단한 개체가 포함된 예. 그림 4에서 감지 출력의 위쪽 행은 실제 학생 모델에서만 실제 학생 모델에서 학습된 것이고, 아래쪽 행의 감지 출력은 모방된 학생 모델에서 나온 것입니다.
교사 감독을 통한 학생 모델의 개선은 다음과 같은 측면으로 요약될 수 있습니다. 향상된 차별 능력.
그림 4(a)와 그림 4(f)에서 보는 바와 같이 남성복 하부의 색상과 스타일은 일부 소파 오브제와 다소 유사하다.
원시 학생 모델은 다소 높은 신뢰도로 소파 개체로 오인합니다. 모방 학생이 오류를 피하는 동안 더 나은 식별 능력을 나타냅니다.
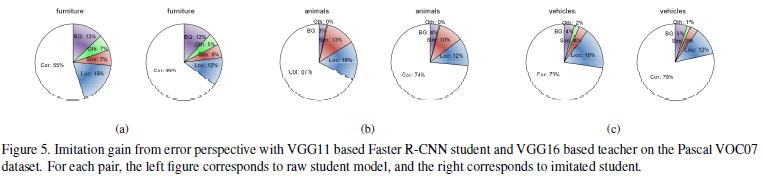
그림 4. 모방 학습의 질적 결과. 경계 상자 시각화 임계값은 0.3으로 설정됩니다. 상단 행 이미지는 모방이 없는 학생 모델의 출력이고 하단 행은 모방 학생의 출력을 보여줍니다.그림 5. Pascal VOC07 데이터 세트에서 VGG11 기반 Faster R-CNN 학생 및 VGG16 기반 교사를 사용한 오류 관점에서의 모방 이득. 각 쌍에 대해 왼쪽 그림은 원시 학생 모델에 해당하고 오른쪽은 모방 학생에 해당합니다
모방된 학생이 원시 학생 모델에 비해 개 인스턴스에 대한 신뢰도가 낮다는 점은 흥미롭습니다. 우리는 교사 모델(VGG16 기반 Faster R-CNN)이 인스턴스에 대해 0.38의 신뢰도를 출력하는 것을 관찰
4.4.4 Varying ψ for generating mask
0.5의 중립 값이 최적인 것으로 판명되었습니다. ψ가 0.5보다 크면 두 학생의 mAP가 감소하기 시작하지만 값이 1.0일 때보다 여전히 높으며, 이 경우 모방은 지상 진실 감독으로만 축소됩니다. ψ가 0.5보다 크면 모방 영역이 빠르게 줄어들고 극도로 작고 희박해 지지만 해당 영역에 대한 모방은 여전히 학생을 크게 향상
4.4.5 Per-channel variance of high level responses
전체 기능 모방이 성능 저하를 일으키는 이유를 이해하기 위해 훈련된 교사 모델에서 모방 기능 맵의 채널당 분산을 계산한다. . 마스크 내 영역의 기능은 더 많은 정보를 제공한다. 컨볼루션은 전체 피쳐 맵에 대한 가중치를 공유하기 때문에 전역 피쳐 응답을 직접 모방하면 불가피하게 배경 영역에서 많은 양의 노이즈 그라디언트가 누적. 또한 전체 기능 모방의 손실 값이 동일한 정규화 방법으로 훈련 전반에 걸쳐 제안된 접근 방식의 10배 이상임을 경험적으로 관찰
5. Conclusion
이 작업에서 우리는 복잡한 객체 감지기의 지식을 더 작은 것으로 증류하기 위해 가까운 객체 앵커 위치에 대한 교사 감지 모델의 피쳐 응답의 interlocation 불일치를 사용하는 구현하기 쉬운 세분화된 피쳐 모방 방법을 개발 가지치기 및 양자화를 포함한 다른 모델 가속 방법과 직교하며 추가로 결합될 수 있습니다.