n = int(input())
count = 1
stack = []; result = []
for i in range(1, n+1): # 데이터 개수만큼 반복
data = int(input())
while count <= data: # 입력 받은 데이터에 도달할 때까지 삽입
stack.append(count)
count += 1
result.append("+")
if stack[-1] == data: # 스택의 최상위 원소가 데이터와 같을 때 출력
stack.pop()
result.append('-')
else: # 불가능한 경우
print("NO")
exit(0)
print('\n'.join(result))
"extend(reversed(right_stack))" 리스트간 합칠 때 사용. reversed도 사용 가능.
" print(' '.join(left_stack)) " 리스트 내 쉼표 제거 시 사용.
test = int(input())
for _ in range(test):
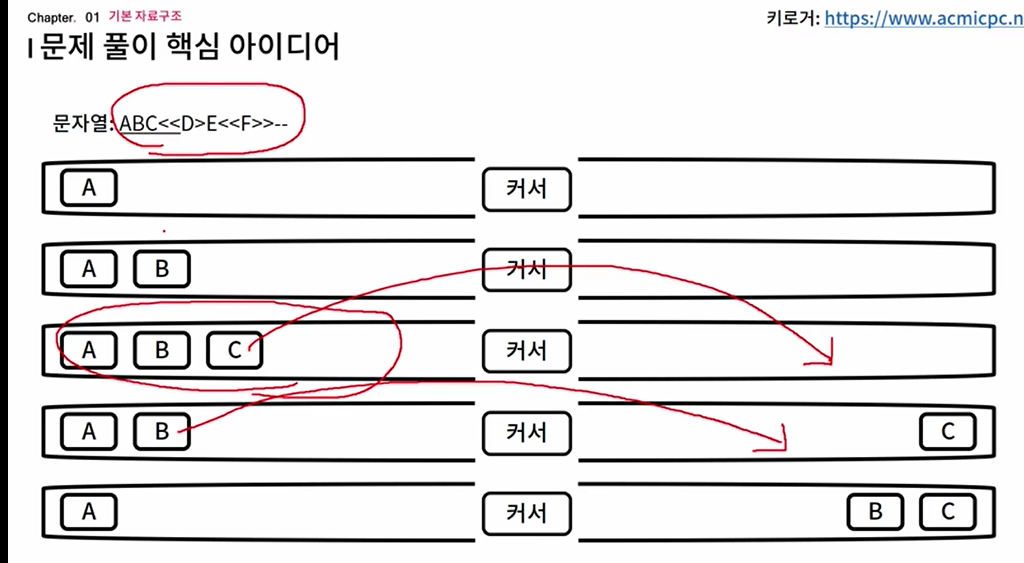
left_stack, right_stack = [], []
data = input()
for i in data:
if i == "-":
if left_stack:
left_stack.pop()
elif i == "<":
if left_stack:
right_stack.append(left_stack.pop())
elif i == ">":
if right_stack:
left_stack.append(right_stack.pop())
else:
left_stack.append(i)
left_stack.extend(reversed(right_stack)) # append()가 아닌 extend()를 통해 확장해서 뒤집어 넣어줌
print("".join(left_stack)) #개별 리스트 쉼표 제거 후 출력